Transparently redirecting packets/frames between interfaces#
Lately I have been consumed by an idea of running container-based labs that span containerized NOSes, classical VM-based routers and regular containers with a single and uniform UX.
Luckily the foundation was already there. With plajjan/vrnetlab you get a toolchain that cleverly packages qemu-based VMs inside the container packaging, and with networkop/docker-topo you can run, deploy and wire containers in meshed topologies.
One particular thing though we needed to address, and it was the way we interconnect containers which host vrnetlab-created routers inside.
Vrnetlab uses its own "overlay datapath" to wire up containers by means of an additional "vr-xcon" container that stitches the exposed sockets. Although this approach allows to re-wire containers in different topologies after the start, this was not something that we could use if we wanted use non-vrnetlab containers in our topology. Ideally I wanted to emulate p2p links between the routers (running inside containers) by veth pairs stretched between them, pretty much like docker does when it launches containers. And that is also the way docker-topo works.
1 Linux bridge and "you shall not pass"#
Michael Kashin in his docker-topo project wanted to do the same, and he proposed to add a new connection type to vrnetlab which used linux bridges inside vrnetlab containers, thus allowing to interconnected vrnetlab containers in a docker-way:
docker create --name vmx --privileged vrnetlab/vr-vmx:17.2R1.13 --meshnet
docker network connect net1 vmx
docker network connect net2 vmx
docker network connect net3 vmx
In a nutshell, this is what was proposed by Michael:
The router VM sitting inside the container connects to container' data interfaces eth1+ by the means of Linux bridges. This approach is the most straightforward one, it doesn't require any additional kernel modules, it is well-known and battle-tested and it has a native support in qemu/libvirt.
But the elephant in the room is a Linux bridge' inability to pass certain Ethernet frames - specifically LACP and STP BPDUs. And apparently LACP support is something that is badly needed in nowadays labs, as people want to test/demo EVPN multihoming. So as easy as it gets, classical bridges can't satisfy the requirement of emulating a p2p link between data interfaces.
Off we go looking for alternatives.
ADD: Apparently, there is a simple way to make LACP to pass over the linux bridge, another great person Vincent Bernard read the mailing list archives and found out that you can only restrict the MAC_PAUSE frames and leave LACP be.
though tc solution is cleaner for the purpose of a point-to-point link.
2 Macvtap#
Another approach that Michael tried when he was working on docker-topo was macvtap interface that looked promising on paper.
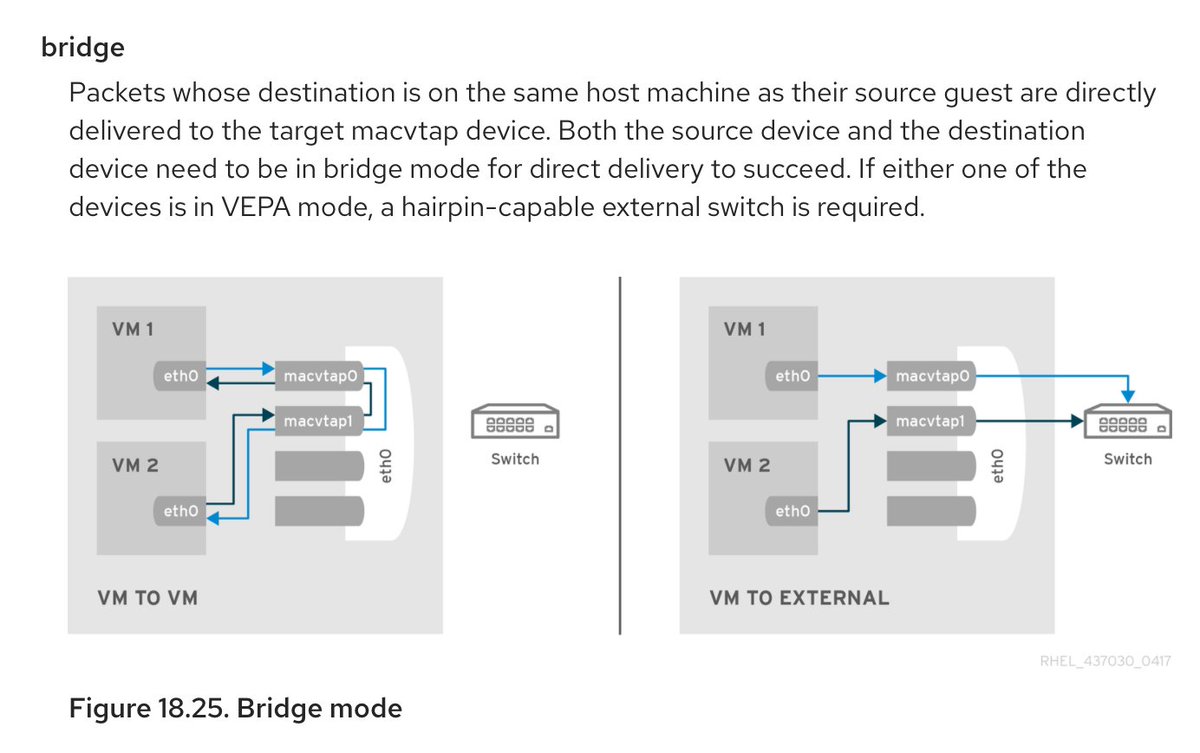
And although
- this approach required to mount the whole
/devto a container namespace, - it had no qemu native support so we had to play with opening file descriptors
we still tried...
...and we failed.
Macvtaps in bridge mode worked, but they were not passing LACP still. No matter what we tried it became evident that path is a no go.
3 Openvswitch#
Most of my colleagues use openvswitch bridges to interconnect classical libvirt/qemu VMs when they need to have support for LACP. With OvS all it takes is a single configuration command:
The reason I didn't want to start with OvS in the first place is that it is like using a sledge-hammer when all you need is to drive through a tiny nail. OvS is heavy in dependencies, it requires a kernel module and sometimes you simply can't install anything on the host where you want to run containers.
But with all other options exhausted, I decided to add this datapath option to my fork of vrnetlab to finally land LACP. And it worked as it should, until I started to hear complaints from users that sometimes they can't install OvS for multiple reasons.
But there was nothing else to try, or was there? We even wanted to explore eBPF path to see if it can help here...
4 tc to the rescue#
Then all of a sudden Michael pinged me with the following message:
@hellt have you seen this? "Using tc redirect to connect a virtual machine to a container network · GitHub" https://gist.github.com/mcastelino/7d85f4164ffdaf48242f9281bb1d0f9b
This gist demonstrated how tc mirred function can be used to solve a task of port mirroring. Isn't this brilliant? That was exactly what we needed, to transparently redirect all layer 2 frames between a pair of interfaces. Pretty much like veth works.
And tc delivered!
With a couple of lines and no external dependencies (tc is part if iproute2 which nowadays ubiquitous) tc made a perfect datapath pipe between VM and container interfaces:
# create tc eth0<->tap0 redirect rules
tc qdisc add dev eth0 ingress
tc filter add dev eth0 parent ffff: protocol all u32 match u8 0 0 action mirred egress redirect dev tap1
tc qdisc add dev tap0 ingress
tc filter add dev tap0 parent ffff: protocol all u32 match u8 0 0 action mirred egress redirect dev eth1
Back in 2010 some RedHat engineer was looking for a way to do port-mirroring on linux host and he explained how tc mirred works, maybe that inspired mcastelino to write that gist that Michael found, but whichever it was, that helped to solve my case of transparently wiring container interface to a tap interface of a VM.
And it was super easy to make it integrated with qemu, since all you need is to create an ifup script for a tap interface:
#!/bin/bash
TAP_IF=$1
# get interface index number up to 3 digits (everything after first three chars)
# tap0 -> 0
# tap123 -> 123
INDEX=${TAP_IF:3:3}
ip link set $TAP_IF up
# create tc eth<->tap redirect rules
tc qdisc add dev eth$INDEX ingress
tc filter add dev eth$INDEX parent ffff: protocol all u32 match u8 0 0 action mirred egress redirect dev $TAP_IF
tc qdisc add dev $TAP_IF ingress
tc filter add dev $TAP_IF parent ffff: protocol all u32 match u8 0 0 action mirred egress redirect dev eth$INDEX
and then use this script in qemu: